


Creating Comment Annotations using the Datalogics PDF Java Toolkit
One of the more interesting features of Adobe Acrobat is the ability to review and markup documents using electronic versions of common tools used to mark up paper documents. Acrobat gives you a highlighter, a sticky note tool, even a paperclip to attach additional documents or files. These are stored as annotation on top of the PDF pages. The Datalogics PDF Java Toolkit allows developers to create, modify, extract and manage these annotations in a way that is completely interoperable with Adobe … Read more

Sample of the Week:
One of the more interesting features of Adobe Acrobat is the ability to review and markup documents using electronic versions of common tools used to mark up paper documents. Acrobat gives you a highlighter, a sticky note tool, even a paperclip to attach additional documents or files. These are stored as annotation on top of the PDF pages. The Datalogics PDF Java Toolkit allows developers to create, modify, extract and manage these annotations in a way that is completely interoperable with Adobe Acrobat.
What You Need to Know First:
Every object on a PDF page that isnt content is, technically, an annotation; links, printer marks, some types of watermarks, embedded movies and 3D models, as well as lines, arrows, highlights. All are annotations but this article only covers the annotations that appear in the Comments panel of Adobe Acrobat.
All of the annotation types can appear anywhere on the PDF page but some of them only make sense when they are associated with words. For example, in Acrobat DC, you can draw on the page with the highlighter tool and when you are not over a word, an Ink annotation gets created and is defaulted to yellow just like a highlighter. However, when you are over a word, the highlighter will act as a selection tool and you can highlight specific words. Acrobat will then create Highlight annotations and use the bounding rectangle of the selection as the bounding rectangle of the highlight. The same effect can be created programmatically using the Datalogics PDF Java Toolkit as is demonstrated in the Gist referenced lower in this article. We can use the ReadingOrderTextExtractor and the WordsIterator classes to gather the words in the document, locate the words we want to highlight and then use some of the coordinate information in the Word objects to create new Highlight annotations.
There are basically two ways to position an annotation on a PDF page.
- A rectangle. The rectangle can either describe the lower-left and upper-right corner of the rectangle that represents the bounding box of the annotation or it can be a single point where the lower-left and upper-right corner are actually the same point. This second type is good for the Sticky Note annotations where the appearance of the annotation is actually the responsibility of the viewer to create.
- A vertex array. Polylines, Polygons, and Ink annotations use an array of X,Y coordinates to define a path that then gets drawn by the AppearanceService. The way that the vertices get connected is defined by the annotation type. Ink annotations get connected with curves, the other two get connected with straight lines.
Its important to note that several of the Acrobat Commenting tools map to the same PDFAnnotation subclasses. For example, lines and arrows both use the class PDFAnnotationLine, arrows just get an extra couple of properties that define where the arrow, or line ending, goes and what it looks like. The Free Text Tool, Typewriter Tool, Text Box, and Callout all use the PDFAnnotationFreeText class.
And Finally, its important to note that not all viewers are equally as capable of interpreting the annotation objects properly and displaying them so its good practice to make the Datalogics PDF Java Toolkit generate the appearances for the annotations at the time of creation. This way, even if a view cannot work with an annotation, it will still be visible.
Creating Comment Annotations using the Datalogics PDF Java Toolkit
The code snippets below show how to add most of the annotation types found in Adobe Acrobat, the full Gist shows more and is commented with more detailed information.
Please click on the images below to enlarge.
Stick Notes:

Highlights:

Strikeout:

Typewriter:
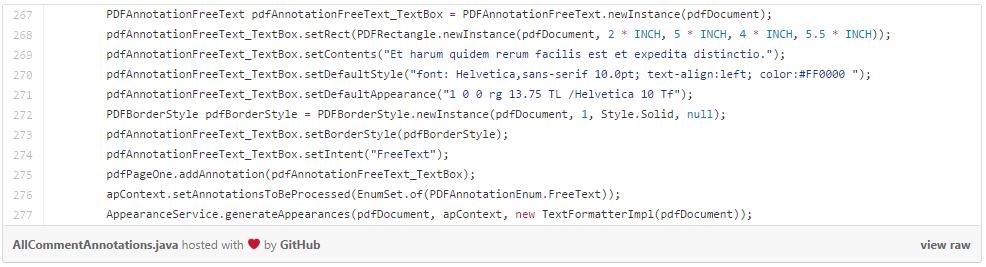
Free Form Draw:
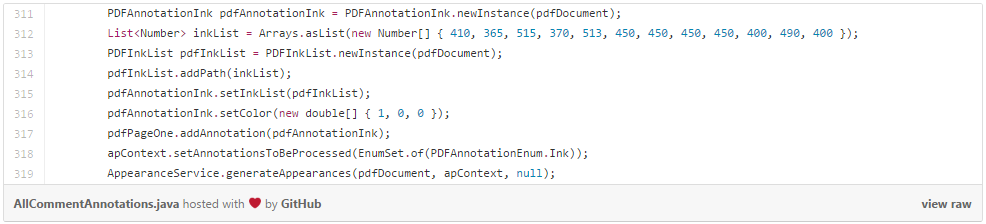
Arrow:
![]()
To get started working with PDF, download this Gist and request an evaluation copy of The Datalogics PDF Java Toolkit.
Datalogics, Inc. provides a complete SDK for PDF creation, manipulation and management for companies around the globe. Built on Adobe source code, our flagship product Adobe® PDF Library offers a choice of programming platforms and languages along with unsurpassed customer service, proven by our 94% customer retention rate. Datalogics offers…
Read more