

Re-Subsetting Embedded Font Subsets
PDF authors often wish for their content to be viewed consistently by their readers, no matter who views their documents or where their documents are viewed. For textual content, font selection and handling plays a particularly important role in achieving consistent results across PDF viewers, platforms, and geographic locations. One of the safest techniques to ensure font consistency is to directly embed fonts in PDF documents, rather than rely on locally installed fonts to be found or substitu … Read more

PDF authors often wish for their content to be viewed consistently by their readers, no matter who views their documents or where their documents are viewed. For textual content, font selection and handling plays a particularly important role in achieving consistent results across PDF viewers, platforms, and geographic locations. One of the safest techniques to ensure font consistency is to directly embed fonts in PDF documents, rather than rely on locally installed fonts to be found or substituted by a PDF viewer.
This method is dependable but comes at a price, as fully embedded fonts can contain vast amounts of information, and PDF file size can scale up quickly with multiple embedded fonts. So, how does one ensure a consistent PDF viewing experience while minimizing document size?
Rather than embedding each font’s entire set of glyphs, one can make use of an optimization technique known as font subsetting which is the practice of removing unused glyphs from embedded fonts in a PDF. This can help to reduce a PDF’s file size by removing font information that is not needed in the document. While the general concept is simple, the implementation of optimal font subsetting can be a complex process.
For example, when multiple PDFs are merged together, the resulting document can include font subsets from each original document. If these font subsets were created from the same base font, they may have overlapping glyphs, which can lead to redundant information and a larger-than-necessary file size. Two of Datalogics products, Adobe PDF Library and PDF OPTIMIZER, are designed to detect these related font subsets and merge them together into one optimal font subset.
But what happens when text is removed from the document after font subsetting? Font subsets can include glyphs that were originally needed but are no longer necessary in the document after it has been modified. With the latest releases of Adobe PDF Library and PDF OPTIMIZER, Datalogics has introduced a new feature that enables embedded font subsets to be re-subset. Just as font subsetting can reduce file size, re-subsetting can further reduce file size after text has been removed from a document.
Imagine we have a thirteen-page document in which each page is labeled with a different letter of the alphabet, from A through M. If these labels represent the only text in the document that uses that specific font, subsetting the font would reduce the number of glyphs embedded in the document down to fourteen (thirteen letters plus a special glyph to handle undefined glyphs). Now imagine if each page of the PDF were saved individually as single-page documents. Re-subsetting the font subsets in each of the thirteen new documents would reduce those font subsets from fourteen glyphs down to just two (one letter plus that same glyph to handle undefined glyphs).
While this is a simple example intended to illustrate the utility of re-subsetting embedded font subsets, the practice can scale to have a dramatic impact on file size in more complex documents, particularly with fonts representing non-alphabetic languages, including Chinese and Japanese, which can contain many thousands of glyphs.
To further illustrate how powerful these savings can be, consider the following example. Let’s start with a PDF called “input.pdf” that contains a full page of text and an embedded font subset:

We can use Adobe Acrobat DC to delete all of the text on the page except for the first two words “Tell me” and save the document as “edited.pdf.”
The embedded font programs are separate file formats embedded in the PDF that typically conform to external specifications. In order to interpret them, we need a tool that is capable of reading the font format and making sense of the data. This information has a relationship to its parent font dictionary object in the PDF. There are various font formats, so it is not a trivial task to interpret them all.
We can use the Preflight feature of Acrobat DC to explore the internal structure of the embedded font program referenced in the document. Within Preflight, there is a menu option to “Browse Internal Structure of All Document Fonts,” seen below:
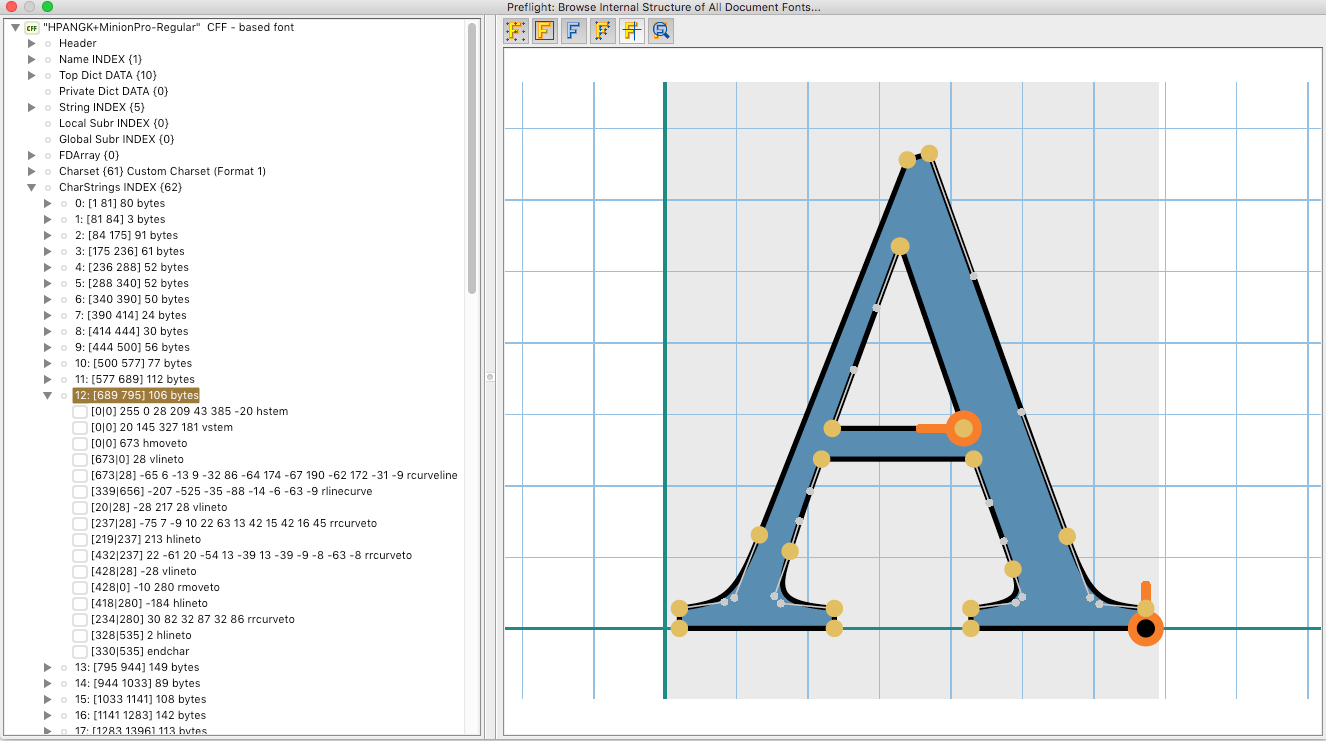
We can interactively explore the font, its properties, and information regarding the various tables, arrays, dictionaries, and values that make up the font program. There is also a visual representation of drawing commands, which can be helpful in debugging font issues.
Notice that there are in fact 62 different CharStrings (A, B, C, D, E, etc.). If we select the “A” glyph, we can see the various segments that draw the glyph. The CharStrings dictionary contains the encoded commands that draw the outlines of the characters included in the font.
Now we can use Datalogics PDF OPTIMIZER to optimize “edited.pdf” with the new font re-subsetting option, which will output a new file to disk, called “optimized.pdf.” When we open this file in Acrobat and examine the CharStrings, we now see there are only six (.notdef, space, T, e, l, m):
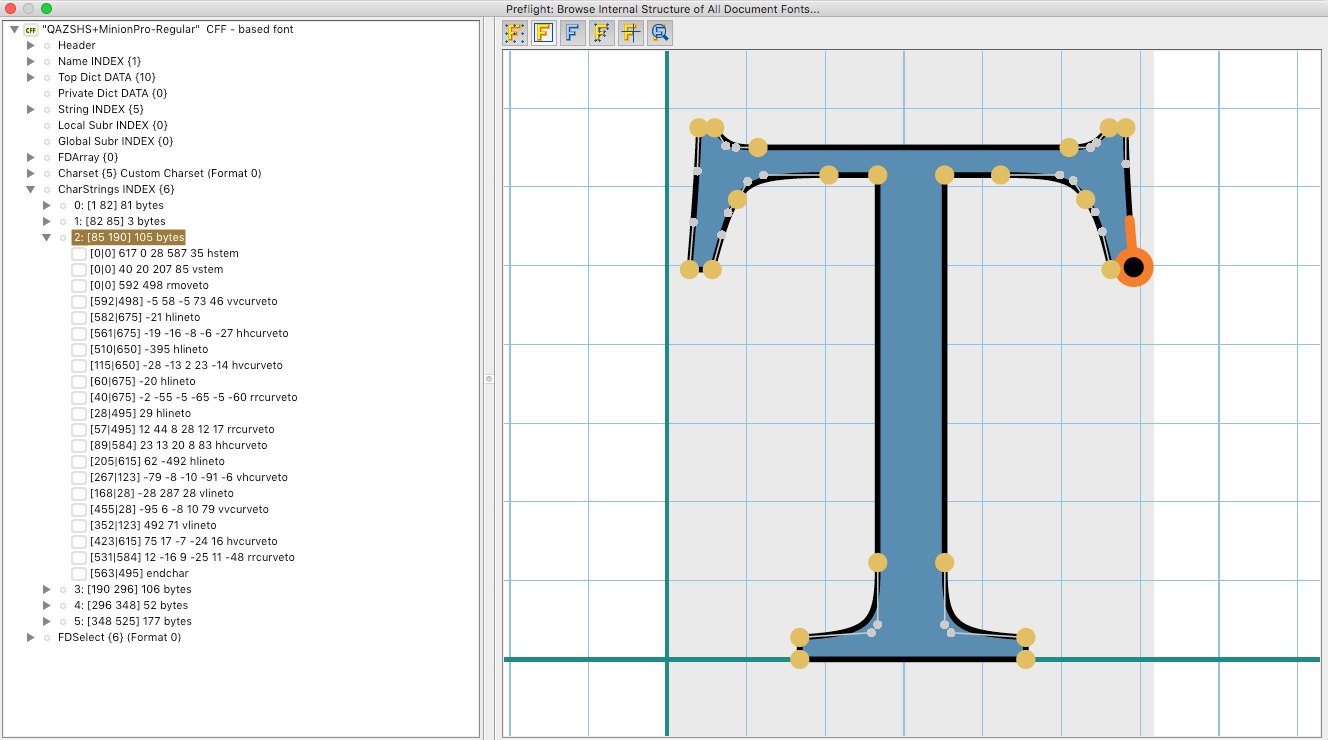
This corresponds to the five glyphs necessary to spell “Tell me” and the .notdef glyph, which should always be included to handle undefined glyphs referenced in the page’s content.
The original “input.pdf” file was initially optimized with an embedded font subset, but after our modification, the “edited.pdf” was no longer optimized. PDF OPTIMIZER’s powerful new feature intelligently analyzed the glyphs actually in use in our document, removed the extraneous glyphs, and created a new font subset to replace the original one, yielding a substantial savings in the size of the embedded font program and ensuring the final “optimized.pdf” balances a consistent viewing experience with a reduced file size.
Through both Adobe PDF Library and PDF OPTIMIZER, Datalogics provides easy solutions to ensure font subsets are as optimized as possible, even when documents are modified after initial font subsetting.
Interested to see what these products can do for you? Click here for a free trial of Adobe PDF Library, and here for PDF OPTIMIZER.
Datalogics, Inc. provides a complete SDK for PDF creation, manipulation and management for companies around the globe. Built on Adobe source code, our flagship product Adobe® PDF Library offers a choice of programming platforms and languages along with unsurpassed customer service, proven by our 94% customer retention rate. Datalogics offers…
Read more